The difference between bolting AI on and building AI in — and why it changes every system you design from here
Every generation of software architects faces a moment of honest reckoning.
The moment when a new capability arrives — and the old architectural instincts quietly stop working.
The question is not whether AI belongs in your system. The question is: where does it live?
Most systems today have AI. Almost none of them are AI-native.
There is a difference. It matters enormously. And understanding it is the most consequential architectural decision you will make in 2026.
The Navigator and the Autopilot
Before GPS, every long-haul vessel had a navigator.
Not a consultant. Not a module. A full-time crew member whose entire job was to track position, plot heading, and feed decisions to the captain. The navigator worked with charts, sextants, dead reckoning. The captain trusted the navigator. The navigator made the system intelligent.
When GPS arrived, most ships did the obvious thing: they put a GPS unit on the navigator’s desk.
The navigator remained. The captain remained. The GPS was consulted — one more input in a workflow that hadn’t fundamentally changed. The ship still moved. The port was still reached. But the architecture of decision-making was unchanged.
Then came the container vessels designed around GPS from day one.
On these ships, course is held by autopilot. Collision avoidance is algorithmic. Fuel optimization is continuous. The human crew watches for exceptions — anomalies the system cannot classify, situations that require judgment the model doesn’t have. The captain is no longer the conductor of a manual orchestra. The captain is a supervisor of an intelligent system.
Same ocean. Same destination. Completely different architecture.
AI-augmented is a GPS on the navigator’s desk. AI-native is a ship built to sail itself.
Your software systems are the same. The question is which kind you’re building.
What “AI-Native” Actually Means — And What It Doesn’t
“AI-native” is not a marketing claim. It is an architectural stance.
| Dimension | AI-Augmented | AI-Native |
| Where AI sits | At the output layer — a feature added to an existing product | In the decision path — a first-class runtime component |
| Retrieval | A search box called before the LLM | A structured service that shapes what the model knows |
| Failure modes | Binary — pass or fail | Statistical — distribution shifts, hallucination rates, faithfulness degradation |
| Observability | Logs and latency | Behavioral telemetry: context utilization, grounding score, output drift |
| Evals | Optional QA step before release | The specification — how you know if the system works at all |
| Data model | Designed first; AI adapted to it | Shaped by the LLM’s input/output contract from day one |
| Human role | Operator of the system | Supervisor of an intelligent system |
The distinction is not about how much AI you use. It is about where AI sits in the architecture itself.
Three Things the Old Stack Quietly Misses
1. Retrieval is not a feature. It is a foundation.
Old-stack thinking treats retrieval as search — a module you call, a box you check. You ingest documents, build an index, call the LLM with the top five results.
AI-native thinking treats retrieval as the primary interface between the world and the model. The retrieval layer determines what the model can know, what it will hallucinate about, and how it handles queries it has never seen. Get retrieval wrong and no amount of prompt engineering saves you.
Retrieval is not plumbing. Retrieval is the foundation.
2. The model is not the product. The pipeline is.
Old-stack architects optimized for the model — fine-tuning, prompt crafting, parameter choices. The assumption: the model is the moat.
In 2026, models are a commodity. They converge. The moat is the eval harness, the retrieval pipeline, the observability layer, the feedback loop that catches drift before your users do. These are the things that separate a demo from a production system.
Good models cannot save bad pipelines. Only good pipelines can save models.
This is not a new idea. But most teams are still building around the model.
3. Failure modes are statistical, not binary.
Old-stack testing is binary: the function returns correctly or it doesn’t. Pass or fail.
AI-native testing is distributional. The model’s outputs drift. Gradually. Silently. Across percentiles, not individual requests. A faithfulness score of 0.94 that quietly becomes 0.81 over six weeks — no single request fails, but the system is degrading.
Old-stack observability is logs and latency. AI-native observability is behavioral telemetry: hallucination rate, context utilization, grounding score, output distribution shift.
If your monitoring cannot tell you whether your LLM is behaving worse than it was last month, your system is not AI-native. It is AI-hoping.
What an AI-Native Stack Actually Looks Like
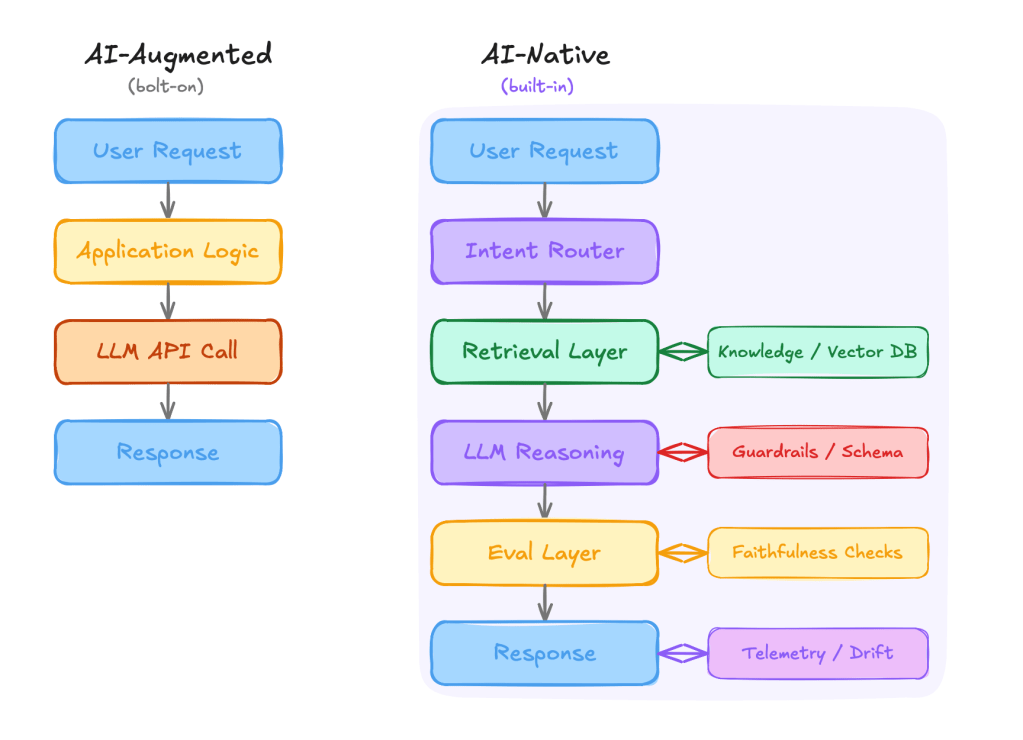
The AI-augmented stack has one arrow pointing to AI. The AI-native stack has AI woven through every layer — intent, retrieval, reasoning, validation, observability. Each layer is designed with the model’s failure modes in mind, not its happy path.
Trade-Off: When AI-Augmented Is the Right Call
I am betting on AI-native. That does not mean AI-augmented is always wrong.
AI-augmented wins when:
- The core product is non-AI and AI adds one discrete, bounded capability (e.g., summarization in a document management system)
- Regulatory or compliance constraints make LLM decisions unacceptable in the critical path
- The team has not yet built literacy around LLM failure modes — shipping AI-native without that literacy produces fragile systems, not intelligent ones
- The deadline is 90 days and the codebase is 3 years mature; a full redesign is not on the table
AI-native wins when:
- The core value proposition depends on LLM reasoning, not merely LLM output
- The system must handle novel, open-ended inputs that no deterministic rule set covers
- The feedback loop — eval, improve, redeploy — is part of the product, not a maintenance task
- You are designing a new system, not extending an old one
The call I’d make: If you are designing a new system in 2026, design AI-native. The cost of retrofitting is higher than the cost of learning the right patterns now. Teams that choose AI-augmented “for now” consistently find that “now” becomes a permanent architectural ceiling.
You cannot retrofit a keel.
Who Is Already Building This Way
| System | What Makes It AI-Native |
| Perplexity | Retrieval is the product — not a feature bolted onto a search engine |
| GitHub Copilot | Your code repository is the retrieval layer; the model reasons over your actual context, not a static index |
| Notion AI | The document graph is the knowledge layer; AI is a first-class citizen of the data model, not an API call at the end |
| AWS Bedrock Agents | Orchestration, tool use, and memory are architectural primitives, not SDK wrappers on top of a Lambda function |
| Glean | Enterprise knowledge retrieval built LLM-first — permissions, staleness, and grounding are solved in the retrieval layer, not patched at the prompt |
Warning Signs You Are AI-Augmented (Not AI-Native)
| Warning Sign | What It Signals |
| Your LLM call is inside a try/except with a generic fallback message | You haven’t designed for LLM failure modes. You’ve hoped they don’t happen. |
| Your eval suite is “we test it manually before each release” | Evals are a post-facto ritual, not an architectural layer |
| Your retrieval is a vector search call with k=5 and no re-ranking | Retrieval is plumbing, not a designed system |
| Your observability dashboard shows latency and error rate — nothing else | You have no visibility into whether your model is behaving correctly, only whether it responded |
| The LLM was added after the data model was finalized | Your schema was shaped by the old product. AI was adapted to it. That gap never closes cleanly. |
Three or more? You are AI-augmented. That is a starting point, not a permanent state.
Architect’s Checklist: AI-Native or AI-Augmented?
Five diagnostic questions. No partial credit. Most readers will fail three of five. That is the point.
| Diagnostic Question | AI-Native Answer |
| Does your system run an eval harness on every deploy — automatically, with measurable thresholds — not manually? | ✅ Yes |
| Is retrieval a first-class service with its own SLA, schema, re-ranking logic, and failure handling? | ✅ Yes |
| Does your observability layer track LLM-specific metrics — hallucination rate, faithfulness score, context utilization — per request and aggregated over time? | ✅ Yes |
| Can your system degrade gracefully — with an explicit, tested fallback path — when LLM output confidence is low? | ✅ Yes |
| Did the LLM’s input/output contract shape your data model, or did you finalize the schema first and add AI later? | ✅ LLM contract came first |
5/5 — AI-native. Build the eval harness you’ve been deferring.
3–4/5 — On the gradient. Start with the eval harness; it unlocks everything else.
0–2/5 — AI-augmented. Name it honestly. It is a starting point, not a destination.
Back to the Ship
Go back to the ship.
The GPS-on-the-navigator’s-desk approach works. Ports are reached. Schedules are met. Nobody on the bridge is filing a complaint.
But when you need to scale — when you are running a fleet of a hundred vessels, when ocean conditions change faster than any navigator can track, when the value you are delivering depends on a thousand micro-decisions per voyage — the GPS on the desk stops being an advantage and starts being a constraint.
The ship built to sail intelligently from the beginning does not have these problems. It has different problems — harder architectural problems, problems worth solving.
The navigator’s desk got a GPS unit and called it the future.
The future was a ship that already knew how to sail.
That is the bet I am making. It is the architecture I am building toward.
Design From Day One
AI-native is not a trend. It is not a label. It is not a job title.
It is a set of architectural decisions — made at the beginning, not retrofitted at the end — that determine whether your system scales, adapts, and improves, or merely runs.
Most systems today are AI-augmented. They work. They ship. They satisfy stakeholders.
They will not survive the next design cycle.
You cannot retrofit a keel.
Design AI-native from day one. Or spend the next two years explaining why you didn’t.
Quick Daily Reminder for Architects
- Evals are the spec — not an afterthought
- Retrieval is load-bearing — not plumbing
- Failure modes are statistical — not binary
- AI-native is a decision — not a destination
~1,900 words · ~9 min read · AI-Native Architecture

Leave a comment